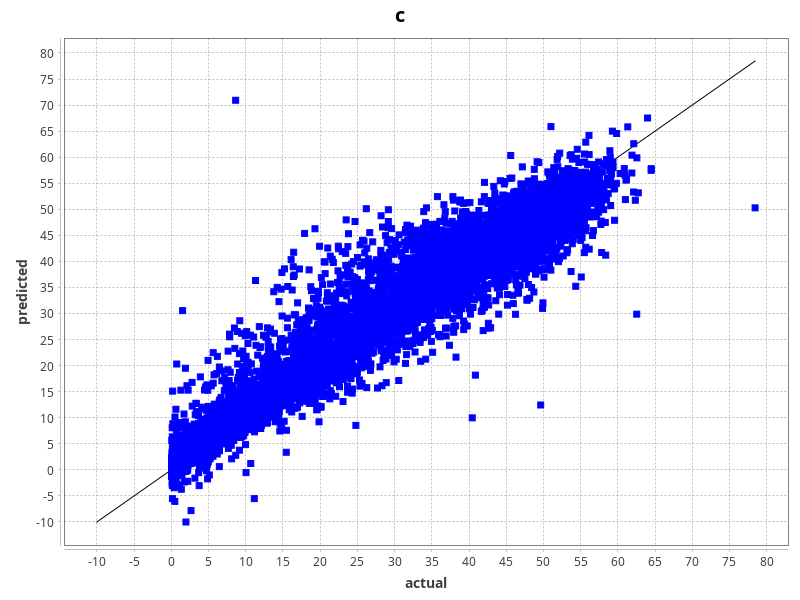
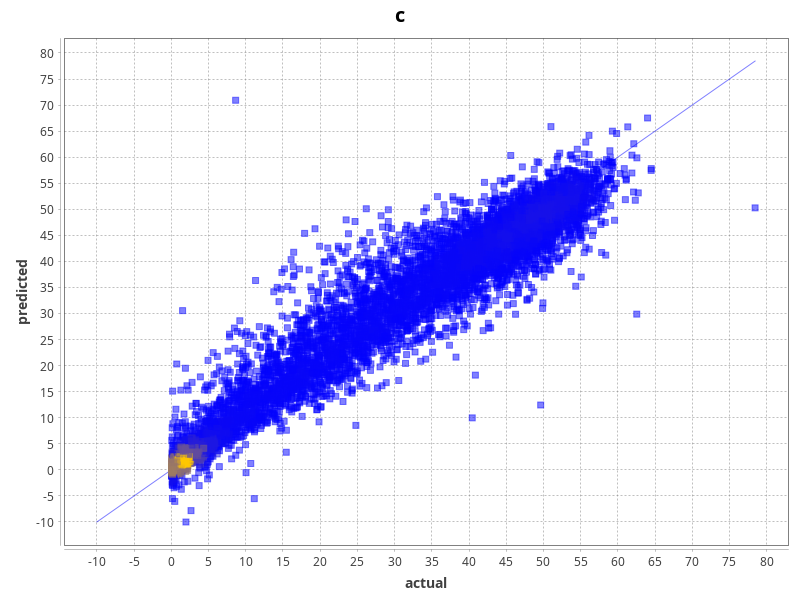
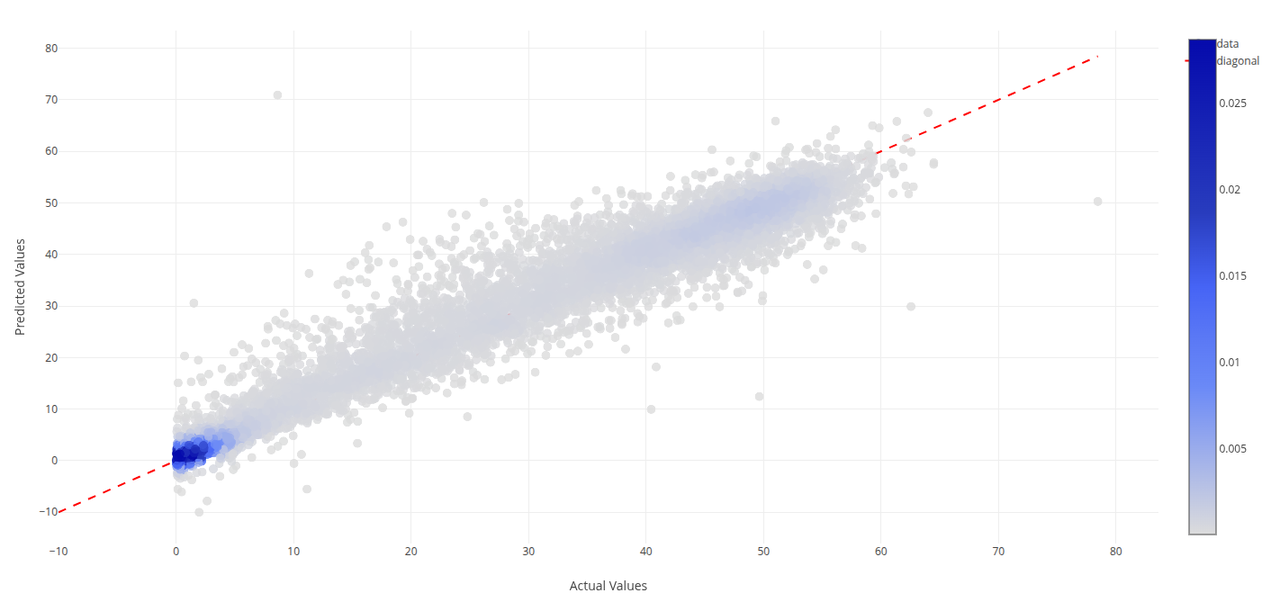
S3000 Pod Support
Typically, our commercial framework for laboratories, S3000, combines training of models/cleaners/evaluators/etc and generating predictions on the same server. But that was mostly due to S3000 instances starting out with a small number of models, not because it was a requirement. Especially for mission-critical systems that output predictions 24/7, it makes sense to have a separate grunty server for training the models and then one or more light-weight servers that serve the predictions.
However, copying the versioned directory structures from the training directory across to other servers is not particularly efficient and it is easy to make mistakes. Especially, if one has to update the setups and/or components as well.
In order to speed up deployments of new models or simply make replacing only a few models easier, S3000 introduces the concept of Pods. A Pod is a self-contained zip file that combines all the serialized models like classifier and evaluators plus a JSON configuration file describing the pod. Prediction generators that are Pod-aware will then read these Pod files and their configuration to generate a prediction workflow on-the-fly which will then load the models into internal storage, ready to be used.
Currently, only SIMPLE components are supported and FUSION will be added at a later stage.